

Lock-Free Queue - Part I
March 22, 2020
While implementing a bounded queue or ring buffer in a single-thread universe is relatively easy, doing the same when you have two threads, the implementation of a lock-free queue is more challenging.
In this first part will analyse and implement a lock-free single-producer single-consumer queue. A multi-producer multi-consumer queue is described in the second part.
In a traditional queue we have two pointers: the head, that points to the next free entry to write and the tail, which points to the next entry ready to be read.

 Full queue. One entry is always left empty to differentiate a full queue from an empty queue.
Full queue. One entry is always left empty to differentiate a full queue from an empty queue.
Other implementations do not waste this entry.
The pointers serve as stop-markers: the producer will not write if the head points to an entry that is immediately before the entry pointed by the tail; the consumer will not read if the tail and the head are pointing to the same entry.
![]() Empty queue. When head and tail pointers are the same there is not ambiguity.
Empty queue. When head and tail pointers are the same there is not ambiguity.
In the first case we say that the queue is full; in the second, the queue is empty.
But if we want to make the queue thread safe without using locks we need to make the push and the pop atomic.
And here is the problem: if a producer store the data and later moves the head, another producer will see the old head in between and store her data in the same place overwriting the first one.
You may think that this cannot happen because we have only one producer.
And you are correct except for the memory reorders.
We cannot longer guarantee that the head was moved after writing the data even if the code say so. Keep reading.
Changing the order doesn’t fix the problem: a producer may move the head before writing, trying to reserve the space but now a consumer may forward the tail before the data was actually written reading entries that are empty.
The problem is that the write and the move of the head is not a single atomic action.
The same happen for reading.
The key to resolve this is to have two heads and two tails.
Reserve-Commit
Both the producer and the consumer need their own head and tail.
The producer moves her head to reserve the space so other writers will begin to write starting from that point.
At the same time the consumer will not forward beyond the producer’s tail.
Only when the producer finishes, she will move forward her tail, commiting the change and allowing the readers to proceed.

The consumer does something similar: moving the consumer’s head reserves the entries to read so other readers will not pop the same data; and the consumer’s tail serves as a stop-marker for the writers.
Now, the trick is in how to move those pointers atomically.
Single-consumer single-producer queue (buggy version)
Pseudo-C code, for simplification. The full code can be found in the loki library.
Let’s draft the push() function:
uint32_t push(struct queue_t *q, uint32_t *data, uint32_t len) {
old_prod_head = q->prod_head;
cons_tail = q->cons_tail;
uint32_t free_entries = (capacity + cons_tail - old_prod_head);
n = (free_entries < len) ? free_entries : n;
if (!free_entries || free_entries < n) {
errno = EAGAIN;
return 0;
}
new_prod_head = (old_prod_head + n);
q->prod_head = new_prod_head;
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
q->prod_tail = new_prod_head;
return 0;
}
As we said before we have the producer’s head and the consumer’s tail pointers.
We load them and check that if there are enough free entries for pushing len data. capacity here is the size of the queue minus one ensuring that a producer’s head will never reach the consumer’s tail in a push.
If we have room, we update the producer’s head to the new value: now the consumer had reserved the space between her tail and head pointers to write the data.
After the write, the producer update her tail pointer so the consumer can move forward and consume the new available data.
Atomic loads and stores
In a single-producer, the head is only modified by a single thread but now, it can be modified by multiple producers.
To ensure a consistent value, the producer’s tail must be updated (store) atomically so the consumer will not read an incomplete value.
This applies for consumer’s head too: the producer must load it atomically.
The compiler may assume that q->prod_tail is never read so it could strip the store off. Under a single thread scenario this is correct; in a multithreading scenario this is a disaster.
In some processors the loads and stores to uint32_t are atomic, however that’s not enough: we also need to prevent the compiler from optimize them.
We really need that those loads and stores happen even if the compiler thinks that they are not needed.
Take at look of what volatile does.
See also the comments about this in cppreference
For that reason we declare them as volatile
struct queue_t {
volatile uint32_t prod_head;
volatile uint32_t prod_tail;
volatile uint32_t cons_head;
volatile uint32_t cons_tail;
// ...
This is what DPDK does while the FreeBSD version assumes loads and stores are atomic.
If the processor cannot guarantee atomic loads and stores, we can instruct the compiler to generate code for that:
old_prod_head = __atomic_load_n(&q->prod_head, __ATOMIC_RELAXED);
//....
__atomic_store_n(&q->prod_tail, new_prod_head, __ATOMIC_RELAXED);
Load and store reorder
Review the following:
We require the size of the queue to be a power of 2: entry access through the head/tail pointer is masked size-1 instead with module of size.
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
q->prod_tail = new_prod_head;
What’s wrong?
The compiler may reorder the store of the tail to happen before the actual write of the data. Even if the compiler does not do that, the CPU may do it.

This is a store reorder. A store is typically much expensive than a load and they are moved upwards to start them sooner or downwards to be delayed hoping to be merged with a further store.
Loads are subject of similar optimizations and the volatile keyword will not prevent that: volatile works at the compiler level, has no effect on the reorder made by the CPU.
Beware that some barriers are at the compiler level only and here we need to ensure that neither the compiler nor the CPU do something too smartish.
We have the option to use a full write barrier in the middle so all the stores that happen before of the tail update are perceived by other threads as if they happen before the update
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
wmb(); // write memory barrier
q->prod_tail = new_prod_head;
Nobody is saying that everything will happen in the same sequential order, just that the notion of A1, A2, … happen before B1, B2, … is preserved.
A1, A2, <barrier>, B1, B2 and A2, A1, <barrier>, B2, B1 are two valid outcomes: reorder on each side of the barrier are perfectly valid (left).
Reorder across the barrier are not (right).
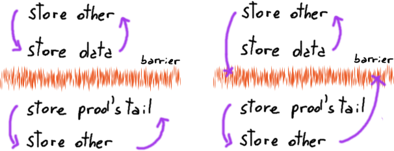
A full write barrier is the nuke option as it prevents any store reorder across that point for all the threads.
A more precise and efficient solution is possible in these days however.
Acquire - Release memory model
Consider the last part of the push and the first part of the pop:
uint32_t push(...) {
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
q->prod_tail = new_prod_head;
}
uint32_t pop(...) {
old_cons_head = q->cons_head;
prod_tail = q->prod_tail;
uint32_t ready_entries = prod_tail - old_cons_head;
n = (ready_entries < len) ? ready_entries : n;
if (!ready_entries || ready_entries < n) {
errno = EINVAL;
return 0;
}
// ...
The producer updates (stores) her tail to signal the consumer that can move forward.
The consumer is waiting until the producer’s tail is moved forward so there are entries ready for reading.
There is no a real wait: the pop() just fails if there is nothing to read but conceptually there is a signal and wait relationship between the producer and the consumer on the producer’s tail pointer.
This is the same that happens when a thread acquires a mutex: other thread will wait on it until the first thread release it.
The modern processors and compilers introduced this concept in the Acquire - Release memory model.
We say that the consumer acquires the producer’s tail and the producer release it.
 “No reads or writes in the current thread can be reordered after this
“No reads or writes in the current thread can be reordered after this RELEASE store. All writes in the current thread are visible in other threads that ACQUIRE (load) the same atomic variable. No reads or writes in those threads can be reordered before that load either.”
From std::memory_order, cppreference.com
While a full barrier ensures a “happen before” across all the threads, the ACQUIRE ensures that all the stores of that thread that happen before the ACQUIRE will be perceived than happen before by only the thread that is doing the RELEASE.
uint32_t push(...) {
// ....
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
__atomic_store_n(&q->prod_tail, new_prod_head, __ATOMIC_RELEASE);
return 0;
}
uint32_t pop(...) {
old_cons_head = q->cons_head;
prod_tail = __atomic_load_n(&q->prod_tail, __ATOMIC_ACQUIRE);
uint32_t ready_entries = prod_tail - old_cons_head;
n = (ready_entries < len) ? ready_entries : n;
if (!ready_entries || ready_entries < n) {
errno = EINVAL;
return 0;
}
// ....
DPDK uses this while the FreeBSD version uses a full memory barrier.
Indeed the RELEASE ensures that the producer’s writes will be visible by the consumer once she ACQUIRE the updated producer’s tail pointer in a much efficient way that a full barrier
Single-producer single-consumer queue (final version)
This is the wrap up: a not only lock-free but a wait-free single-producer single-consumer queue (or ring).
For those how want something compilable, the final bits are in the loki library.
uint32_t push(struct queue_t *q, uint32_t *data, uint32_t len) {
old_prod_head = q->prod_head;
cons_tail = __atomic_load_n(&q->cons_tail, __ATOMIC_ACQUIRE);
uint32_t free_entries = (capacity + cons_tail - old_prod_head);
n = (free_entries < len) ? free_entries : n;
if (!free_entries || free_entries < n) {
errno = ENOBUFS;
return 0;
}
new_prod_head = (old_prod_head + n);
q->prod_head = new_prod_head;
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
__atomic_store_n(&q->prod_tail, new_prod_head, __ATOMIC_RELEASE);
return n;
}
uint32_t pop(struct queue_t *q, uint32_t *data, uint32_t len) {
old_cons_head = q->cons_head;
prod_tail = __atomic_load_n(&q->prod_tail, __ATOMIC_ACQUIRE);
uint32_t ready_entries = prod_tail - old_cons_head;
n = (ready_entries < len) ? ready_entries : n;
if (!ready_entries || ready_entries < n) {
errno = EINVAL;
return 0;
}
new_cons_head = (old_cons_head + n);
q->cons_head = new_cons_head;
for (uint32_t i = 0; i < n; ++i)
data[i] = q->data[(old_cons_head + i) & mask];
__atomic_store_n(&q->cons_tail, new_cons_head, __ATOMIC_RELEASE);
return n;
}
Open questions
In the FreeBSD queue the push() and pop() are wrapped with critical_enter() and critical_exit(). I’m not sure exactly why. From the thread safety point of view, they should not be necessary but they may be there for some reason.
References
Kip Macy implemented a buffer ring for FreeBSD. It was the base foundation for DPDK’s rte_ring.
Both were used as references along with
- Release-Acquire ordering, cppreference.com
- GCC Atomics, gcc.gnu.org
- Ring library, doc.dpdk.org
- C++ and Beyond 2012: Herb Sutter - Atomic Weapons - Part 1
- C++ and Beyond 2012: Herb Sutter - Atomic Weapons - Part 2
References at March 2020.
Related tags: performance, lock free, data structure, queue