

Lock Free Queue - Part II
April 28, 2020
If implementing a lock-free queue for only one producer and consumer is tricky, adding more producers and consumers moves this to the next level.
This is the continuation of the lock-free single-producer single-consumer queue
Not only we need to prevent race conditions between the producers and the consumers but also between producers and between consumers.
Race between producers
Recall the first part of push(): we load the producer’s head, and calculate if we have enough room for the incoming data and if we have, we update the producer’s head to the next position.
uint32_t push(struct queue_t *q, uint32_t *data, uint32_t len) {
old_prod_head = q->prod_head;
cons_tail = __atomic_load_n(&q->cons_tail, __ATOMIC_ACQUIRE);
uint32_t free_entries = (capacity + cons_tail - old_prod_head);
n = (free_entries < len) ? free_entries : n;
if (!free_entries || free_entries < n) {
errno = ENOBUFS;
return 0;
}
new_prod_head = (old_prod_head + n);
q->prod_head = new_prod_head;
// ...
Consider now what would happen if we have two producers: both will compete in a race to put what they think that it is the new value of head.
More over the space reserved for both will overlap leading to a memory corruption.

What we need is the load, compute and store on q->prod_head as a single atomic operation. This is called read-modify-write operation.
Or compare and exchange
No builtin atomic exists for that but we can built one with a compare and swap instruction.
Move the head/tail forward atomically - CAS loop
uint32_t push(struct queue_t *q, uint32_t *data, uint32_t len) {
old_prod_head = __atomic_load_n(&q->prod_head, __ATOMIC_RELAXED);
do {
cons_tail = __atomic_load_n(&q->cons_tail, __ATOMIC_ACQUIRE);
uint32_t free_entries = (capacity + cons_tail - old_prod_head);
n = (free_entries < len) ? free_entries : n;
if (!free_entries || free_entries < n) {
errno = ENOBUFS;
return 0;
}
new_prod_head = (old_prod_head + n);
success = __atomic_compare_exchange_n(
&q->prod_head, // what we want to update,
&old_prod_head, // asumming that still have this value,
new_prod_head, // with this value as the new one.
false,
__ATOMIC_RELAXED,
__ATOMIC_RELAXED
);
} while (!success);
// ...
Note that I said “it still has the same value”; I did’t say “the value did’t change”. For our queue it doesn’t matter but for other structures it is really important and the confusion leads to the ABA problem
The idea is to do an atomic read, do all the modifications and checks that we need and then do an atomic write with the new value only if the head is still pointing to the same position that we read.
That is what __atomic_compare_exchange_n is about.
If it is, it means that no other producer moved the head and we can proceed.
There is no need to do an explicit atomic load again, __atomic_compare_exchange_n will do it for us if it fails.
If not, we need to retry again until we succeed.
This loop makes the push() to take an unbound number of steps (loop iterations) until it can proceed. The queue is lock-free but no wait-free anymore.
Waiting for others
Once a producer finished the write it releases it updating the producer’s tail to the new head.
uint32_t push(...) {
// ...
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
__atomic_store_n(&q->prod_tail, new_prod_head, __ATOMIC_RELEASE);
return 0;
}
However we have another race condition here.
It is not about the store of the value, we can use an atomic store for that; it is about the order of the stores.
Both producers have the correct notion of the next head thanks to the CAS loop however this is only truth if the first producers updates the tail before the second one.
Recall that the producer’s tail is the marker for the consumers to stop, preventing them to read undefined data.
If the second producer updates the tail there are not guaranties that the first producer finished her writing by then; she didn’t released the memory reserved.
If the producer 2 updates the tail before the producer 1, the consumers may read that the producer 1 may not had written yet.
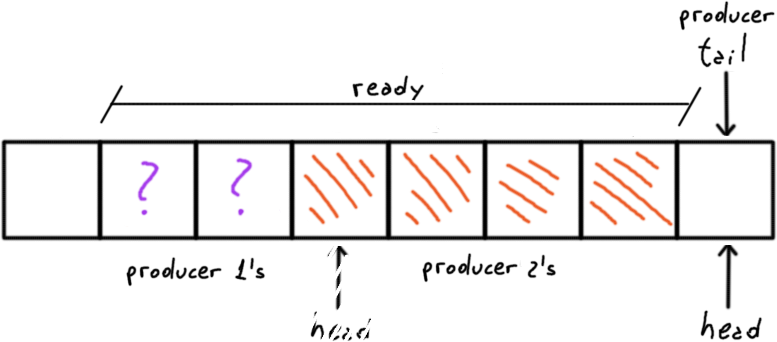
What we need is to enforce an order: all the previous push() must complete before a producer update the tail.
We can get this waiting until the tail reaches the old head meaning that any reserved space for writing (between the tail and the old head) was used and released.
So the next block reserved begins at the old head/current tail and ends at the new head.
uint32_t push(...) {
// ...
// write the data
for (uint32_t i = 0; i < n; ++i)
q->data[(old_prod_head + i) & mask] = data[i];
// loop until the tail reaches our original head.
// ensuring that no other previous push is still in progress
while ((volatile uint32_t)(q->prod_tail) != old_prod_head) {
// Tell the CPU that this is busy-loop so he can take a rest
loki_cpu_relax();
}
__atomic_store_n(&q->prod_tail, new_prod_head, __ATOMIC_RELEASE);
return 0;
}
Multi-producer multi-consumer queue (final version)
The code can be found in the loki library.

Future research on the busy waits
The push(), and analogously the pop(), has two busy waits: the CAS loop for update the head and the wait-for-others for updating the tail in order.
Both loops have an impact on the parallelism depending of different factors.
It is expected to have more contention in the CAS loop as the number of producers increase, especially when the data written is small.
On the other hand, it is expected to have more time wasted on the wait-for-others loop when the data is larger as this should dominate the time needed to complete one push() and therefore preventing to complete the next ones.
In a future post I will explore this.
More readings:
- preemptive nature of ring algorithm (DPDK)
- cbloomrants’ posts about threading
- H Sutter’s Effective Concurrency seriers
- Jeff Preshing’s posts
Other implementations
I didn’t have the chance to explore this, but the Thomasson’s MPMC queue followed another approach based in a linked list.
The documentation says that it has lock free pop() and wait free push().
The only downside is that requires a double-word CAS instruction.
Open questions
The DPDK’s ring buffer adds a fence between the read of the old producer’s head and the read of the consumer’s tail and I cite:
“Ensure the head is read before tail”
uint32_t push(struct queue_t *q, uint32_t *data, uint32_t len) {
old_prod_head = __atomic_load_n(&q->prod_head, __ATOMIC_RELAXED);
do {
/* Ensure the head is read before tail */
__atomic_thread_fence(__ATOMIC_ACQUIRE);
cons_tail = __atomic_load_n(&q->cons_tail, __ATOMIC_ACQUIRE);
uint32_t free_entries = (capacity + cons_tail - old_prod_head);
/* rest of the CAS loop */
} while (!success);
// ...
The thread fence synchronize with the atomic ensuring that the head stored by one producer is visible by the load of another.
Is it possible for a producer to load a head too old? By the moment of the load another producer had already stored a new value but it is still not visible by the former.
If that is possible the former producer will compute an incorrect free_entries.
What about the CAS instruction? If the producer didn’t see the updated value by the time it does the CAS instruction, it will be setting the wrong head value just as if the CAS loop wasn’t there.
Am I missing something? – Probably.
References
Kip Macy implemented a buffer ring for FreeBSD. It was the base foundation for DPDK’s rte_ring.
Also GCC Atomics, gcc.gnu.org and my previous post lock-free single-producer single-consumer queue.
Also:
- C++ and Beyond 2012: Herb Sutter - Atomic Weapons - Part 1
- C++ and Beyond 2012: Herb Sutter - Atomic Weapons - Part 2
References at March 2020.
Related tags: performance, lock free, data structure, queue