

Compiler Optimizations under a Race Condition
February 7, 2020
When two or more concurrent tasks perform non-atomic read/write operations over the same data we have a race condition and the system will be in an undefined state.
But what exactly does that suppose to mean? What is behind the generic undefined state?
Consider the following code
void* loop(void *p) {
struct ctx_t *ctx = p;
int *data = ctx->data;
int n = ctx->n;
for (int j = 0; j < ROUNDS; ++j) {
for (int i = 0; i < DATASZ; ++i) {
while(data[i] % 2 == n);
++data[i];
}
}
return NULL;
}
The loop function will run in two separated threads. One will increase by one each value of the array if the previous value was even, the other will do the same but if the previous value was odd.
To synchornize the efforts of these two, the code has a busy wait, a while-loop that will run until the condition is set.
The data array is not protected so this will lead to a race condition.
Let’s compile & run it:
$ gcc --version
gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516
$ gcc -std=c11 -lpthread -O0 -ggdb -DDATASZ=256 -o rcO0 rc.c
$ ./rcO0 0 1
Sum 5120
The array of DATASZ == 256 numbers is initially zeroed. Two threads increment each value by one ROUNDS == 10 times.
The displayed number is the sum of the values that should give 256 * 10 * 2 == 5120.
Surprisingly the code seems to work computing the correct result.
I ran several times and I always got the same.
But the party begins when we compile with the optimizations enabled: -O3 flag in gcc.
This time, the optimized program hangs – every time.
Dissection of an optimized RC
Let’s see what code gcc generated.
For the non-optimized code rcO0, the following picture shows the busy loop while(data[i] % 2 == n);:
mov eax, [rax] reads the array and cmp checks for the condition.
If it is not set, the jz jumps to the begin of the loop again.
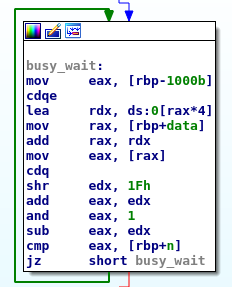
We can see how the program retries again and again until the condition is set before proceeding.
But for the optimized code, the story is totally different.
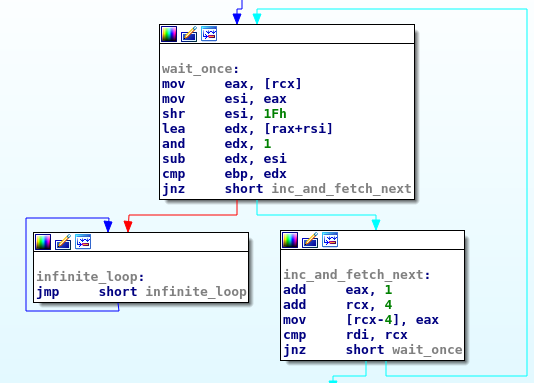
A race condition leads to an undefined state and for a compiler this opens the door for optimizations.
Unless explicitly noticed, the compiler will assume that the code is single threaded.
if (data[i] % 2 == n)
while (1);
++data[i];
If the while-loop waits for a different value but it does not change it, nobody will change it ever so, unless the condition is set from the begin, it is an infinite loop.
So the compiler decided to rewrite it as a single check and an infinite loop that explains why the program hangs.
Volatile
Writes (stores) too: a compiler could optimize issuing only the last of many writes if not read (load) happen in between or it could issue one of them if all of them write the same value.
volatile disables these assumptions.
C and C++ has the volatile qualifier that instructs to the compiler to not assume that reading twice the same variable could yield the same result even if no apparent write happen in between.
volatile int *p pointer to volatile-data; int * volatile p volatile pointer to data. They are not the same.
We could define a pointer to the volatile data:
void* loop(void *p) {
struct ctx_t *ctx = p;
volatile int *data = ctx->data;
...
for (int i = 0; i < DATASZ; ++i) {
while(data[i] % 2 == n);
++data[i];
}
...
You can generalize this cast as a macro READ(x) ((volatile typeof((x)))(x))
Take at look at Linux’s READ_ONCE for a more complete construction even for non-atomic/non-primitive variables.
Or we could use volatile in a cast:
void* loop(void *p) {
struct ctx_t *ctx = p;
int *data = ctx->data; /* non-volatile */
...
for (int i = 0; i < DATASZ; ++i) {
while(((volatile int*)data)[i] % 2 == n);
++data[i];
}
...
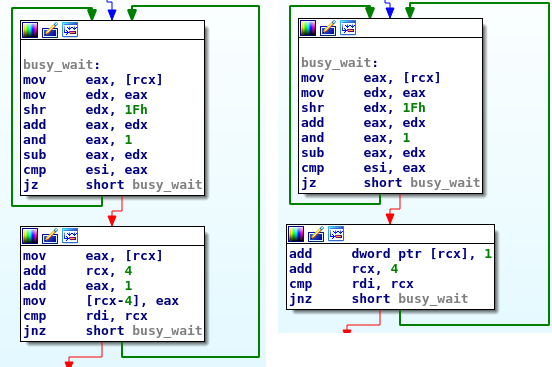
In the first case, any further read of or write to data will not be optimized by the compiler; while in the second case only the read of the array element will not be optimized.
This is something that have an impact on the code generated.
Even if the two programs run correctly, the latter case is slightly more efficient.
data was defined as volatile int*; on the right, when only the read ((volatile int*)data)[i] was affected by volatile.
Both codes were generated with -O3: they are faster than the generated by -O0 but slower than -O3 without volatile, still yielding the correct result.
Notice how ++data[i]; was optimized on the right.
Conclusions
A race condition leads, by definition, to an undefined behaviour.
And the compiler will take this as an opportunity for optimize the code even if that goes against the developer’s desires.
volatile prevents some of these optimizations but the race condition is still there and therefore the undefined behaviour.
This means that other parties like the CPU may perform optimizations and volatile will not help us.