

Effects of CPU Cache Coherence
February 15, 2020
Most modern cpus see a single shared main memory seeing the same thing, eventually.
This post explores what is behind this “eventually” term.
Consider the following function.
It is executed by two threads that increment by one the values of an array one at time: one waiting for even numbers before incrementing, the other waiting for odd numbers.
void* loop(void *p) {
struct ctx_t *ctx = p;
int *data = ctx->data;
int *counters = ctx->counters;
int n = ctx->n;
for (int j = 0; j < ROUNDS; ++j) {
for (int i = 0; i < DATASZ; ++i) {
int cnt = 0;
while(data[i] % 2 == n) {
++cnt;
}
++data[i];
counters[i] = cnt;
}
}
return NULL;
}
The threads synchronize themselves with a busy-loop but the shared array ctx->data is not protected in any way so there is a race condition there.
As we saw in a previous post we can avoid any corruption due the RC for this so simple program if we don’t allow the compiler to optimize the code.
$ gcc --version
gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516
$ gcc -std=c11 -lpthread -O0 -ggdb -DDATASZ=8 -o rccnt rccnt.c
If the two threads see the same value eventually, how much “time” does it take?
That is the purpose of counters: track how many cycles took see the expected value at each index.
How many times a busy-loop cycled gives us a rough estimation.
See man page of pthread_attr_setaffinity_np
To play with different cpus, the program sets the cpu’s affinity of each thread configurable from the command line.
For example, to set the affinity of both threads to the cpu number 0 we do:
$ ./rccnt 0 0
4960841 0 0 0 0 0 0 0
4846049 0 0 0 0 0 0 0
Sum 160
For this post I ran several times the program with all the possible combinations of cpus; scripts and the dataset are here.
CPU contention
Let’s plot what happens when both threads want to use the same cpu:
>>> sns.catplot(x='arr_ix', y='cycles', color='b',
... data=d[d['cpu'] == d['2nd cpu'] == 0])
DATASZ==8 elements); in the y-axis the amount of cycles need until the value got the correct parity.
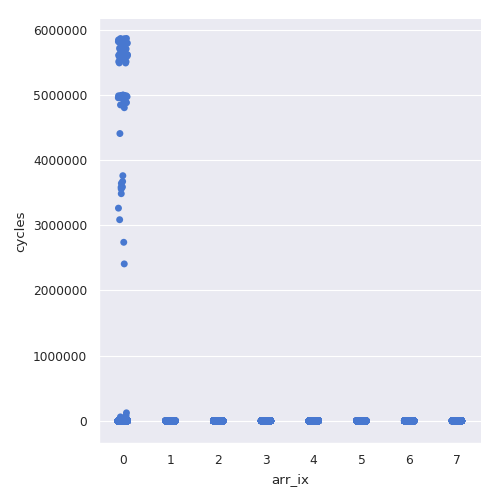
Weird?
Assume that the first thread accesses to its cpu.
This thread checks for even numbers and because the array is initialized to zero it has a free pass to increment their values without busy-looping once.
But after the first round, it will restart again and now all the values are set to 1 so it will need to wait.
The second thread will not run immediately because the cpu is still in use by the first thread.
We have a contention scenario.
Without voluntary yielding the execution, the first thread will not release the cpu; only after a while the OS scheduler will kick it off.
Once that, the second thread runs freely until it finishes the round and starts the next one again falling in the same contention scenario.
That explains why there is a huge amount of cycles before accessing the first element and zero for the rest.
Shared and Private Caches
When both threads run in the same cpu they have an immediate visibility of the modifications done by the other.
But what happen when the threads run in different cpus?
>>> sns.catplot(x='2nd cpu', y='cycles', color='b',
... data=d[(d['cpu'] == 0) & (d['2nd cpu'] != 0)])
Each point represents the cycles that happen in one array access in one execution of rccnt.
Note how values around and greater than 1000 are outliers.
Outliers are only a small fraction of the overall set (~0.413%); I presume that these are because a thread is waiting while the other has no access to the cpu because the OS scheduler decided to give the cpu to another process.
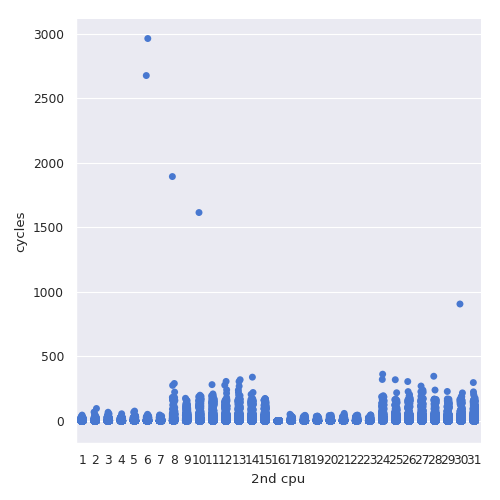
Interesting pattern: when the second thread runs in the cpus from 1 to 7 and 16 to 23 require less iterations than other cpus.
They can see the effects of the first thread sooner.
This is an artifact of having a shared and private caches.
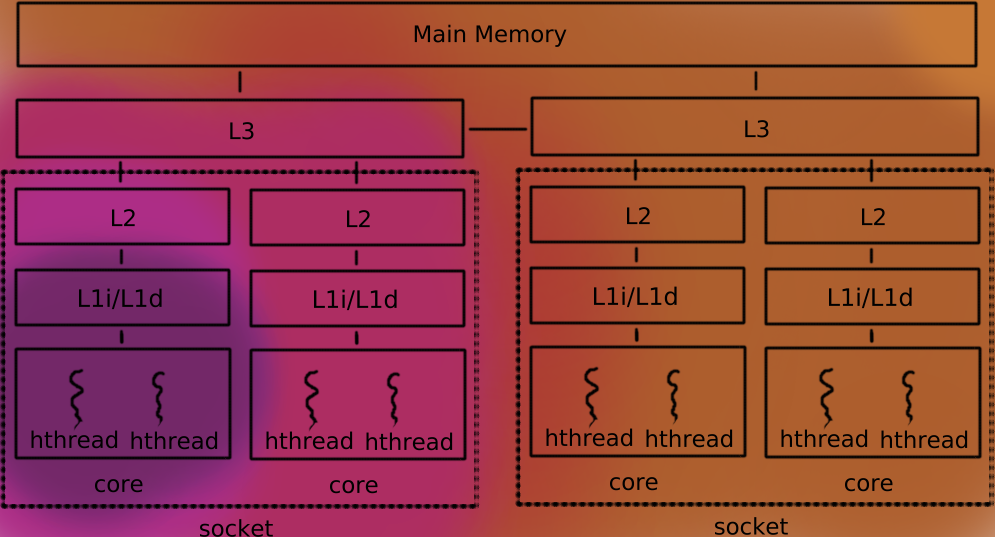
Modern hardware has several cores per cpu die or socket.
The reality is that this is not standard: the details depends of the technology and vendor and changed over the time.
For this post I will assume that L1 and L2 are per socket and L3 shared for all the sockets.
While all the cores share the same L3 cache, each socket has its own private L1 and L2 caches shared by only the cores of that socket.
Cache coherence
When a thread does a store/write it modifies its closest cache: L1.
The same thread does a load/read to that address, it will read exactly that value.
But other threads will read that value eventually.
Consistency and store/load reordering is for another post.
This is a coherent system. It talks about how the stores are visible to other threads but not necessary in which order.
Having a coherent system is critical for today’s code that relay in a unified and shared view of the memory regardless of which thread is running in which core.
But each core has its own private L1 and L2 caches and each socket its own L3 cache: a store in one core will affect its L1 immediately but the store will take some time to be visible to L1/L2 caches of other cores in the same socket and a little longer to be visible in the caches of other sockets.
“Multicore Cache Coherence” (in the reference) explains how to achieve this.
To have a coherent view of the memory, the caches synchronize themselves
Let’s see the effects of this comparing each cpu against the other.
>>> x = d[d['cycles'] < 1000].groupby(['cpu', '2nd cpu']).mean()
>>> del x['arr_ix']
>>> x = x.unstack()
>>> x = x['cycles']
>>> sns.heatmap(x)
cycles > 1000) are ignored and the mean is used as the aggregation function.
The major diagonal (when both threads use the same cpu) has the lowest values but this is because we removed the outliers so it is not entirely correct.
The other two minor diagonals also have the lowest values but this is not the product of removing outliers.
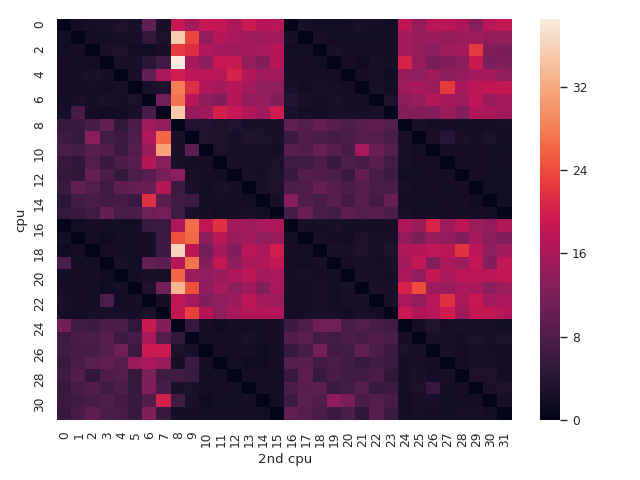
The heatmap corroborates the clustering: cpus 0 to 7 and 16 to 23 can see the effects of the other thread in the same cluster sooner than the other cpus. The same for the other cluster that spans cpus 8 to 15 and 24 to 31.
When the two threads are in separated clusters not only they spend more cycles looping but also it seems that the amount of cycles is more unpredictable.
This is more like a hunch.
This makes the heatmap almost symmetric with some squares slightly brighter than their counterparts.
This is the effect of having separated caches.
But the heatmap reveals something else!
Hyper-threading
There are two minor diagonals that have the lowest cycles values and cannot be explained by the caches.
It happens when we use the pairs 0 and 16, 1 and 17, 2 and 18 and so on.
Those pairs are hyper-threads of the same core.
Paralellism is perhaps too optimistic. Even if the same core can run multiple things, several components are mutually exclusive used. Concurrent is a better word.
Modern cores do instruction level paralellism and execute two or more threads.
In this case, we have 2 hyper-threads per core, sharing the same L1.
Open questions
We used an array of 8 elements of int that gives us 32 bytes. Current technology uses cache lines of 64 bytes. Will the results in this post change if we use larger arrays?
We saw how two threads running in the same cpu fight each other because none yields the cpu; sched_yield is POSIX function to relinquish the cpu. What would happen?
The heatmap was not entirely symmetric. Does it mean that we need to collect more data and try to understand and suppress the noise, or is there something else?
What about NUMA (Non Uniform Memory Address)? Could the results shown in this post be explained by it?
Conclusions
The modern architectures present the memory as a single shared unit; caches are put in between the memory and the cpus to match the difference in speed.
If a multithread application runs, the caches may have different values for the same addresses so a coherency mechanism is put in place.
But it is not free and changes done by one thread take longer to be seen by the other when running in different cores, especially in different cpu sockets.
And the things gets worst if two thread modified memory addresses that are near each other and both fit in the same cache line. Because the cache coherence works line by line, a store in one position will invalidate the cache of other threads that have that dirty line even if they are not using that particular address. This is known as false sharing and it can degrade the performance a lot under specific circumstances.
These conclusions highly depend of the hardware and may not apply to all the systems but this post shows how complex can get such a simple thing like a cache.
References
Multicore Cache Coherence (Lecture 17), John P. Shen. October 25, 2017.
Avoiding and Identifying False Sharing Among Threads, Intel, November 2, 2011
Related tags: reversing, performance, cache, CPU