

Sparse Aware Optimizations for Terminal Emulator Pyte
July 15, 2022
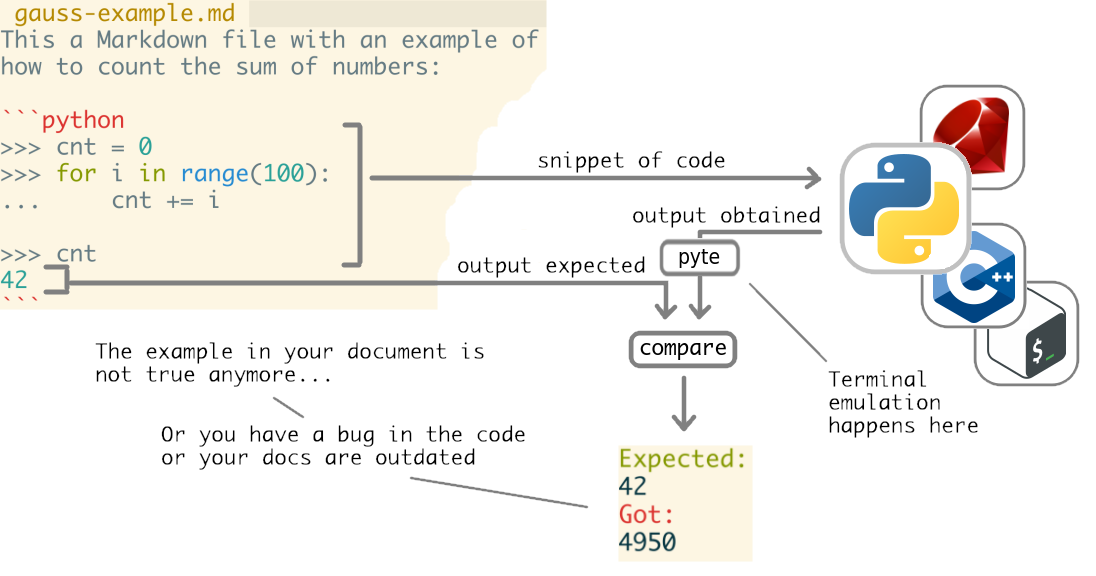
byexample is a tool that reads snippets of code from your documentation, executes them and compares the obtained results with the expected ones, from your docs too.
If a mismatch happen we say that the example in your documentation failed that could mean one of two things:
- your code (the snippet) does not do what you expect so it has a bug
- or the code does exactly what it is supposed but you forgot to update your doc.
Very useful for testing and keep your docs in sync!
But byexample does not really execute anything by itself. Having to code an interpreter for Ruby, Java, C++ and others would be insane.
Instead, byexample sends the snippets of code toa standard interpreter like IRB for Ruby or cling for C++.
Interpreting the output from they is not always trivial.
When a interpreter prints to the terminal, it may write special escape/control sequences, invisible to human eyes, but interpreted by the terminal.
That’s how IRB can tell your terminal to output something with reds and blues colors.
That’s how byexample’s +term=ansi is implemented.
byexample has no idea of what the hell those control sequences are and relays on a terminal emulator: pyte
byexample sends the snippets to the correct interpreter and its output feeds pyte.Screen. It is the plain text from the emulated terminal what byexample uses to compare with the expected output from the example.
But pyte may take seconds to process a single output so byexample never enabled it by default.
This post describes the why and how of the optimizations contributed to pyte to go from seconds to microseconds.
Artifacts and artificial boundaries
Using an emulator like pyte saves us from interpreting the escape/control sequences, but introduces some unwanted artifacts in the output.
For example, considere the following snippet that prints a single line of "A". If you do this in your terminal you will see that the line spans multiple lines.
>>> print("A" * 170)
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAA
Why? It’s because your terminal has boundaries, a finite width in this case and lines longer than that are cut and continued on the next line.
This is super handy for a human but not for byexample.
Another artifact is the limit of lines in the terminal: if the interpreter outputs a lot of lines only the last will be visible “on the screen” and the rest will be lost.
>>> for i in range(30):
... print(i)
22
23
24
25
26
27
28
29
Again, your terminal has a finite height so the same goes for the pyte emulator.
The hack
If the size of the emulated screen generates unwanted artifacts, the hack is simple: increase the size!
And pyte has no problem with that.
Well, actually, it has….
Bad news: it is super slow!
pyte implements a sparse buffer so technically it should not have problems when we increase the size of the screen.
Even if the geometry is of 2400 lines by 8000 columns, the performance of pyte should depend only on the amount of non-empty data in the screen.
Sadly, the algorithms for terminal emulation are not sparse aware and they do full scans.
To give you an example, if a line of 8000 columns has only 5 characters, only 5 characters are stored on memory (good) but displaying it iterates over the whole 8000 columns
>>> @property
>>> def display:
... for y in range(self.lines):
... for x in range(self.columns):
... self.buffer[y][x] # display the char
pyte runtime complexity runs quadratic with respect the size of the terminal and not linear with respect the real data stored within.
Moreover, the underlying implementation of buffer is a defaultdict.
While initially it may contain only the real characters and being very sparse, as soon you do a single full scan the buffer will contain all the entries possible of 2400x8000.
buffer will not be sparse but completely dense. And this of course means the memory also grows quadratic.
Make pyte really fast!
With 54 commits (more than 10% of the total commits that pyte 0.8.1 has), the pull request implements a lot of improvements.
The TL;DR post with the contributions and the results is posted somewhere else but here is a summary.
Sparse-aware scans
First, every time that pyte needs to iterate over non-empty lines or chars, use sparse aware iterations.
Instead of doing:
... for y in range(self.lines):
... line = self.buffer[y]
... for x in range(self.columns):
... line[x] # do something
Do this:
... non_empty_y = sorted(self.buffer)
... for y in non_empty_y:
... line = self.buffer[y]
... non_empty_x = sorted(line)
... for x in non_empty_x:
... line[x] # do something
Both buffer and line are dict with row indexes/column indexes as keys for each non-empty line/char respectively.
The full scan with the nested range is \(s^2\) in terms of any possible slot in the buffer, empty or not.
In contrast, the sparse-aware variant has the cost of sorted (\(n log(n)\)) and the iteration (\(n\)) both in terms of the non-empty data.
When the buffer is sparse we expect \(n ≪ s\) and the second code is way faster than the first.
If buffer is not sparse, both code are quadratic.
Sparsity
So it is critical to maintain the sparsity of the buffer, not only because it consumes less memory (less real entries in the dict) but because the runtime of other algorithms depend on that!
Now, in pyte 0.8.1, the buffer is a defaultdict so any read may potentially write an entry.
Consider the following index method that moves all the lines one row up so a line at coordinate y=8 will be moved to y=7:
def index():
# [...]
bottom, top = 0, self.lines-1
for y in range(top, bottom):
self.buffer[y] = self.buffer[y + 1]
self.buffer.pop(bottom, None)
Simple, elegant but…. for each empty entry at y + 1, we will creating 2 real entries into the buffer: one for writing into index y and one for reading y + 1.
These are what I called false entries.
A single call to index will turn the buffer into a dense, full of false entries dict.
The solution is to replace the full scan for y in range(top, bottom) for one that that iterate only the non-empty entries (avoiding then reading empty entries):
def index():
# [...]
bottom, top = 0, self.lines-1
non_empty_y = sorted(self.buffer)
self.buffer.pop(top, None)
to_move = non_empty_y[begin:end]
for y in to_move:
self.buffer[y-1] = self.buffer.pop(y)
The call to buffer.pop removes the entry and the buffer[y-1] = stores it back in the new index avoiding reading or writing any false entry.
Once all the algorithms are reimplemented, we must change buffer from a defaultdict to a dict to prevent any accidental false entry.
Binary searches
When resize is called and if the screen shrinks, all the lines of the screen are truncated to the new width.
def resize(self, lines, columns):
# [...]
if columns < self.columns:
for line in self.buffer.values():
for x in range(columns, self.columns):
line.pop(x, None)
# [...]
Popping out all the x entries that are greater than the new columns is correct but we can do it better.
You see, most of the entries in the line will not exist really and pop will have no effect on the line (except consuming time!).
With a binary search we can find in \(log(n)\) the first non-empty x and delete from there.
def resize(self, lines, columns):
# [...]
if columns < self.columns:
for line in self.buffer.values():
non_empty_x = sorted(line)
begin = bisect_left(non_empty_x, columns)
for x in non_empty_x[begin:]:
line.pop(x)
# [...]
Technically this is still \(O(n)\) but it should be iterate over lesser entries than the former 0.8.1 version.
The good old Python tricks
At least for 3.10, Python still does not cache any attribute lookup so a easy win is to it ourselves, specially with the lookup is in a for-loop:
def resize(self, lines, columns):
# [...]
buffer = self.buffer
if columns < self.columns:
for line in buffer.values():
non_empty_x = sorted(line)
pop - line.pop
begin = bisect_left(non_empty_x, columns)
for x in non_empty_x[begin:]:
pop(x)
# [...]
Now, we have an additional low-hanging fruit: the inner for-loop calls repetitively the same function over a sequence.
Does that ring any bells to you?
Replacing a loop with a map moves the loop into C and because dict.pop is in C too, it is even faster:
def resize(self, lines, columns):
# [...]
buffer = self.buffer
if columns < self.columns:
for line in buffer.values():
non_empty_x = sorted(line)
pop - line.pop
begin = bisect_left(non_empty_x, columns)
list(map(pop, non_empty_x[begin:]))
# [...]
Don’t do what you don’t need
pyte tracks which lines were modified in a dirty set but byexample (and maybe other users) does not need it.
byexample renders the whole screen as a single string calling screen.display so it does not care what lines changed or not.
For the same reason emulating things like colores and styles is pointless.
As part of the optimizations now pyte can optionally disable those.
“faster”, but how much faster?
All the gory details are in the TL;DR post but here is a quick summary:
At minimum, a humble 2 times faster for small geometries but for large geometries the speed up goes up to 7 times faster and if the screen is tuned, up to 12 times.
An for screen.display, the speed up is insanely huge: 600000 times! But it has a more modest common case of 10 to 200 times faster.
Memory usage was also optimized from 1.10 and 50 times better.
Not everything was improved however: some test cases had a small regression and one had up to 5 times slower (boomers) but in general there was a lot of profit on the improvements.
Related tags: python, pyte, byexample, optimization, performance