

RC-on-XDP-RX-Queue
November 29, 2020
Picture this: you’d been developing for six months a network sniffer using XDP, a kernel in-pass in Linux.
Six months and when you are about to release it, you find not one but three bugs that shake all your understanding of XDP.
A debugging race against the clock begins.
We were hitting three issues in a row:
- RX queue returns addresses with the incorrect offset
- More packets hold by the application than possible
- Pointer to
NULLdata
All of them at random times but very often.
XDP RX queue
The XDP RX queue is a lock free single-producer, single-consumer queue where the kernel plays the role of the producer and the user application the consumer.
The kernel pushes addresses (offsets respect the UMEM’s base address) into the queue that points to the received packets.
The pop has three parts:
- the user application calls
xsk_ring_cons__peekto know how many packets are ready to be consumed. - then, for each one a call to
xsk_ring_cons__rx_descto get the packet’s descriptor and therefore, its address (addrfield) - and finally a call to
xsk_ring_cons__releaseto mark the descriptors free to be reused by the producer.
There is no need to process the packets before xsk_ring_cons__release: releasing the packets’ descriptors of the RX does not make the UMEM’s frames holding the packets free to be reused.
Only when the packets’ addresses are pushed into the fill queue (FQ) the frames are available again.
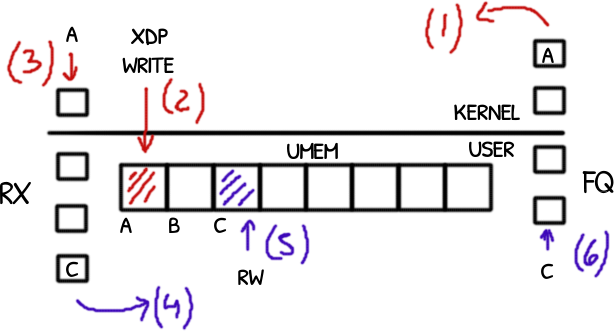
The packet descriptor returned by xsk_ring_cons__rx_desc has two attributes: the packet’s address and its length.
The address is an uint64_t offset respect the UMEM’s base address.

The UMEM is a memory pool divided evenly by 2048 or 4096 bytes, the frame size and addresses are aligned to the frame size plus an offset for a headroom.
The headroom is an application defined space reserved at the begin of the frame for whatever the user wants to do. By default it’s zero.
Well, for some reason the RX queue was returning sometimes addresses with the wrong offset.
More than possible
The UMEM is a fixed memory pool divided evenly in frames where each frame holds a packet.
Therefore the count of packets that the application can hold before releasing them is fixed (UMEM size / frame size).
At anytime the count is less than or equal to UMEM size / frame size.
However the counters of the application shown a different thing: more packets where entering in the application and were hold before releasing them than the expected!
Pointer to NULL
As mentioned before you can prepend metadata to each packet.
In our case, one of the attributes is a pointer to an external structure and the pointer is never updated again. Remains constant.
But to our surprise the pointer changes and leaves pointing to NULL.
And the code is extraordinary simple and straightforward so there is no chances to change the pointer to NULL by an error in the logic.
void do_work(void *ctx) {
while (alive) {
struct pkt_t *pkt = read_packet(); // pull from the RX queue
pkt->obj = external_object();
assert (pkt->obj); // not NULL
/* moments later */
use(pkt->obj->field); // segmentation fault, pkt->obj is NULL
free_packet(pkt); // push into the FQ queue
}
}
No chances.
Debugging
So far we have three unrelated bugs. While possible, it is unlikely that we are dealing with three independent bugs.
They must be related somehow.
Let’s spin a debugger.
Counting before a crash
How many packets were pulled from the RX queue before getting one crash.
(gdb) b read_packet
(gdb) ignore 1 1000000When the bug is detected, GDB will stop and we’ll have the chance to see how many times the breakpoint was hit before.
(gdb) info break
<...>breakpoint already hit 29 timesWould this change in function of the UMEM size? Larger UMEMs has more frames.
These are the results:
// Minimum size, UMEM can hold 1 frame only
breakpoint already hit 29 times
breakpoint already hit 19 times
breakpoint already hit 23 times
// Slightly larger UMEM, it can hold 16 frames
breakpoint already hit 69 times
breakpoint already hit 43 times
breakpoint already hit 50 times
// 64 frames
breakpoint already hit 111 times
breakpoint already hit 69 times
breakpoint already hit 126 times
// 256 frames
breakpoint already hit 348 times
breakpoint already hit 324 times
breakpoint already hit 1 timeSo, with larger UMEMs is less likely to hit the bug but it is not a hard rule. In the last test, with the largest UMEM, we hit the bug in the first try.
Spontaneous addresses
What about the addresses returned by the RX queue? We want to print them without stopping the process.
(gdb) b do_work.c:16 // after the call to read_packet()
(gdb) commands
> silent
> p pkt - umem->base
> cont
> endThe segmentation fault due the NULL pointer happen even when the addresses had the correct offsets (pkt - umem->base % frame_size == headroom_size)
For the ones with incorrect offset, the address most common was the 0 (pkt - umem->base == 0).
I hypothesized that I could be putting the address 0 by mistake in the FQ. Further testing shown that the 0 was never put in FQ but still being received in the RX queue.
So the RX queue was returning addresses that I never put in the FQ. Those are new addresses!
That explains the issue number 2: the application having more packets than it should.
Later, I found that 0 was not the only addresses with an incorrect offset (issue number 1).
Poison values
Let’s print the packets as soon as they are read and the external object is set:
(gdb) set print pretty on
(gdb) b do_work.c:19 // after the call to external_object()
(gdb) commands
> silent
> p *pkt
> cont
> endThe last packet printed before the segmentation fault (issue 3) was something like this
{
timestamp = 121212121,
length = 60,
data = 0xsomeaddress
}And after the crash, the same packet looked like this:
{
timestamp = 0,
length = 60,
data = 0x0
}So the timestamp and data where zero’d. Was this done by the application or something else happen?
Perhaps a rouge memset?
The fields are initialized to zero by the eBPF filter and overwritten by the application.
I decided to set them to non-trivial values, called poison values.
If a memset zero’d them, I will notice.
This is the packet after the crash:
(gdb) p/x pkt->timestamp
0xdead
If you didn’t realize, the timestamp was not zero’d either.
{
timestamp = 57005,
length = 60,
data = 0xbeaf
}So the whole structure was not zero’d but reset, overwritten by the eBPF filter when the packet was supposed to be managed by user.
The three bugs are symptoms of the same unknown problem: the RX queue is returning invalid addresses, not only without the expected offset but addresses that belong to packets that the kernel still thinks that are free.
The real bug
Something was wrong in the RX queue / kernel side so we started to search this issue in the web.
A college of mine found a candidate: the fix of a race condition in the generic receive path.
eBPF runs in the driver if this one supports it. If not, eBPF is executed in the kernel and the packets take a slightly larger path from the network card to user.
This path is known as the XDP generic path or just XDP generic.
Remember than the RX is a single-producer queue so it is not thread safe for concurrent pushes.
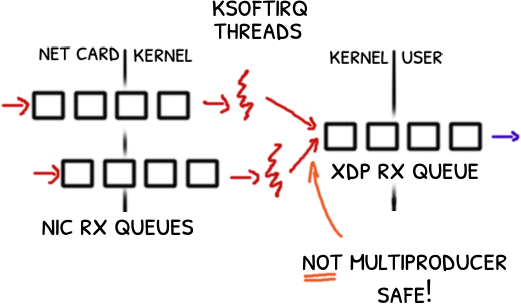
No problem when XDP runs in the driver but when it does in the generic mode, the kernel may be receiving several packets and pushing them concurrently into the RX queue.
“Unlike driver mode, generic xdp receive could be triggered by different threads on different CPU cores at the same time leading to the fill and rx queue breakage. For example, this could happen while sending packets from two processes to the first interface of
vethpair while the second part of it is open withAF_XDPsocket.Need to take a lock for each generic receive to avoid race.” commit bf0bdd13
The commit fixes the issue using a spinlock but the fix was not backported.
And doing a kernel upgrade is not an option.
Single queue
The article Monitoring and Tuning the Linux Networking Stack: Receiving Data explains this wonderfully.
Despite the name, the articule describes all the network stack from the driver to a TCP/UDP socket.
Once a packet is received by the network card a interruption is signaled. The interruption runs briefly and delegates the rest of the processing to a kernel thread named ksoftirqd/n.
The packet is put by the interruption into a queue to be consumed by a single ksoftirqd/n thread.
How the kernel can process multiple packet in parallel?
With multiple queues of course!
If we cannot upgrade the kernel we must enforce a single producer thread in the kernel side.
Configuring the interface to use a single RX queue the kernel will use a single ksoftirqd/n thread, a single-producer.
Try sudo ethtool -L <iface> combined 1 if the other does not work.
Thankfully the configuration is one liner:
$ sudo ethtool -L <iface> rx 1
Conclusions
This was hard. One innocently expects the bugs in the user application, not in the kernel.
And most of the time that’s true!
Debugging confirmed the opposite. And it was not easy.
The do_work shown is an oversimplification. The real code decouple the read_packet from the processing from the free_packet into a serie of threads.
And if debugging a multithreading application is not hard enough, putting a breakpoint in some places added enough delay that the bug was not trigger anymore.
GDB’s set non-stop on helped to reduce the impact: when a breakpoint is hit by a thread, only that thread is stopped.
A special thanks to my college Mario that dug into kernel’s git log and found commit bf0bdd13.
That was the missing piece to solve this puzzle.